Dual Microphone Voice Activity Detection Based on Reliable Spatial Cues
Soojoong Hwang1, Yu Gwang Jin2, and Jong Won Shin1,*
1School of Electrical Engineering and Computer Science
Gwangju Institute of Science and Technology, Gwangju, Korea
2AI Technology Unit, SK Telecom, Seoul, Korea
Dual microphone voice activity detection
Voice activity detection (VAD) determines if the speech signal is present in the current frame or not. Although many single channel VAD approaches have been proposed, multiple microphone VADs can have a better VAD performance by utilizing the spatial cues such as the interchannel level difference (ILD) and the interchannel time difference (ITD). The main purpose of this demo page is to verify the performance of the dual microphone VADs through the additional experiments in a more reverberant room in comparison with the recording room described in the paper. The experimental results include the waveforms of clean and noisy speech, the spectrogram, the ground truth of voice activities, the performance of the several VADs, and the performance indices.
The environmental details and the data
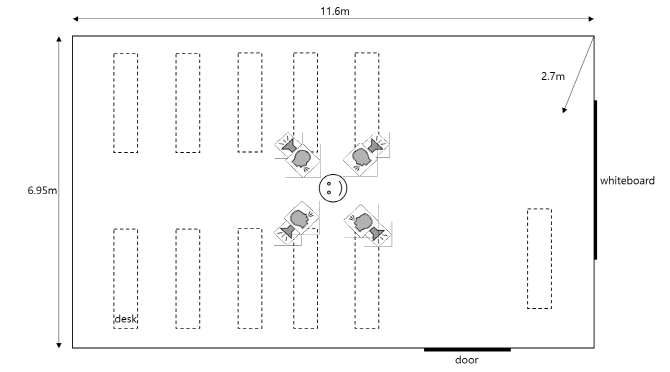
The room size for lectures is 11.6x6.95x2.7m3 and the reverberation time is about 400~500ms. The location and the direction of the target-speaker and the four loudspeakers are depicted in the figure below. Several furniture such as desks and one whiteboard are shown at the figure, but all chairs are not depicted for high visibility.
The diffused field was generated by playing back white, babble, and car noises from NOISEX-92 at the four loudspeakers. And the directional interferences consisting of two female and two male from TIMIT came from the loudspeakers facing the user at the four directions {45˚, 135˚, 225˚, 315˚}. In the center of the room, the desired speech, the directional interferences, and the diffuse noises were individually recorded in a handset mode holding a commercial mobile phone, Samsung Galaxy S9+. 3 minutes of the clean near-end utterances were mixed with those interferences and noises in 6 signal to noise ratio (SNR) levels from -5dB to 20dB with 5dB step, resulting in 126 minutes of the test set.
Abbreviations of the simulated VAD methods
AMR : Adaptive multi-rate VAD option 2
NDPSD : the normalized difference of power spectral density
LTIPD : the long term information of interchannel phase difference
SVM : VAD based on support vector machine using ILD- and ITD-related features
└ SVM-based VAD used the model from the training data set only in the room with low reverberation.
AND : VAD using the logical "AND" operation of the voice activities from ITD and ILD
The VAD methods having a superscript 'FS' indicate the frequency selective versions of the existing VAD methods.
Experimental details
The mask parameters were set to minimize the equal error rate (EER) on the training set in the room with low reverberation. The distance between two microphone of Samsung Galaxy S9+ is about 160mm.
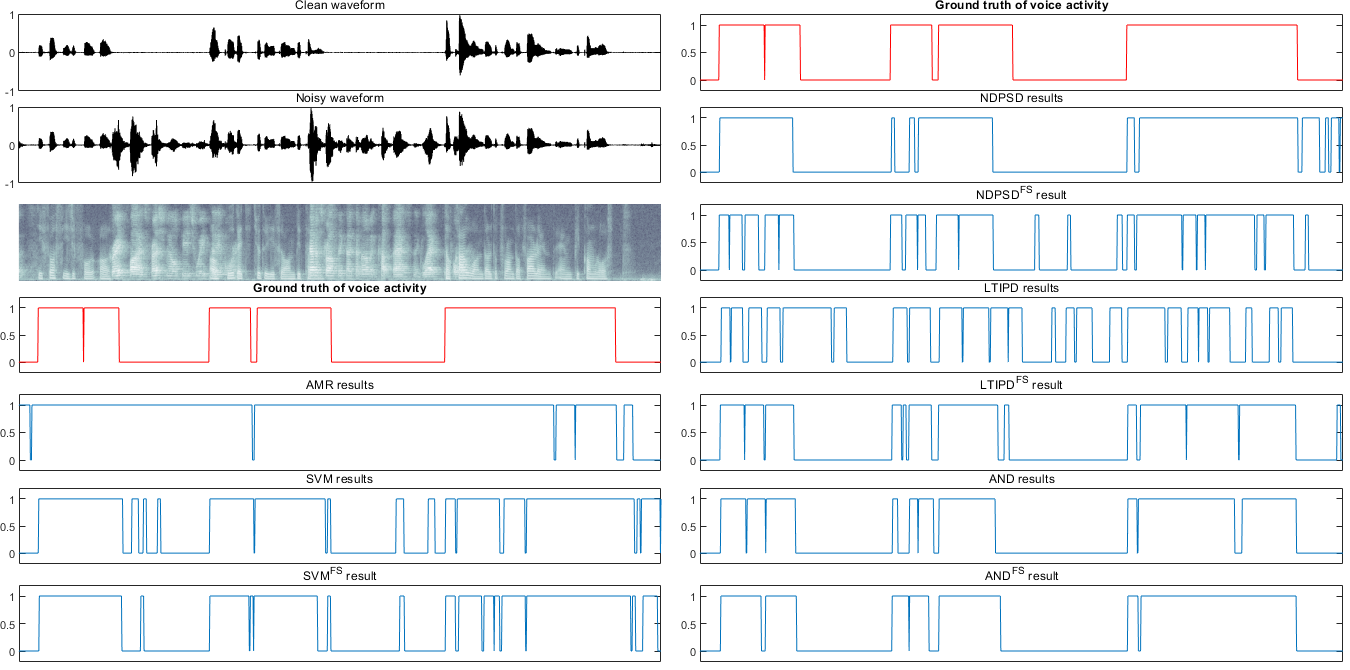
Examples of voice activities from each method
The thresholds and hangover for each VAD were set to the values at the operating point minimizing EER.
45 15dB.wav
135 -5dB.wav
135 5dB.wav
225 10dB.wav
315 0dB.wav
white 5dB.wav
Click the file name (noise_type SNR.wav) to see the results.
Performance - accuracy, hit rate, false alarm rate (FAR)
The performance in terms of accuracy, hit rate, and FAR of each VAD method was evaluated at the operating point minimizing Eovr=α*FRR+(1-α)*FAR and α=0.8 [4].
| method |
AMR |
NDPSD |
NDPSDFS |
LTIPD |
LTIPDFS |
SVM |
SVMFS |
AND |
ANDFS |
| Accuracy |
80.05 |
76.46 |
80.73 |
81.74 |
88.21 |
76.82 |
77.83 |
86.07 |
91.20 |
| Hit rate |
93.81 |
89.68 |
94.63 |
95.96 |
93.09 |
83.40 |
92.83 |
95.59 |
95.61 |
| FAR |
39.27 |
42.08 |
38.78 |
38.22 |
18.64 |
32.41 |
42.23 |
27.28 |
14.98 |
Conclusions
- It may give the better performance to use the same model phone or generally set the parameters.
- The experimental results show that the frequency selective approach still enhances the performance of the existing VAD methods, even if some parameters are not fully optimized. This may be because the parameters are fairly related to the gesture in the handset mode and may be set loosely.
References
[1] 3GPP TS 26.104, ANSI-C code for the floating-point Adaptive Multi-Rate (AMR) speech codec, Rev. 12.0.0, 2014.
[2] M. Jeub, C. Herglotz, C. Nelke, C. Beaugeant, and P. Vary, "Noise reduction for dual-microphone mobile phones exploiting power level differences," Proc. IEEE Int. Conf. Acoust., Speech, Signal Process., Aug. 2012.
[3] Y. Guo, K. Li, Q. Fu, and Y. Yan, "A two microphone based voice activity detection for distant talking speech in wide range of direction of arrival," Proc. IEEE Int. Conf. Acoust., Speech, Signal Process., Aug. 2012.
[4] Park, Y. G. Jin, S. Hwang, and J. W. Shin, “Dual microphone voice activity detection exploiting interchannel time and level differences,” IEEE Signal Processing Letters, Oct. 2016.
Last update : (document XSS header updated.)